|
If you've run Ceph clusters for a long time, you probably either finished or are going through a Filestore to Bluestore conversion. For big clusters with lots of objects, it's a very long process. One of our oldest clusters has been converting for over a year, and it still isn't finished yet. It's a complicated function of object size, number of objects, EC settings, storage speed, etc. A few places probably built a parallel cluster(s) out and copied the data between them. We've done that in a few places, but there were a few business needs that required conversion in place. For that large cluster, we chose the "whole host replacement" method described here: https://docs.ceph.com/en/latest/rados/operations/bluestore-migration/#convert-existing-osds. This method works, is safe, and it's supported by RedHat if you're under commercial support. There's one problem with that article though. It doesn't tell you how to put your spare host back into the cluster once you're done. It tells you to kick a node out with this command: One would think it would be as simple as running the opposite, right? Well sorta. The command is indeed "ceph osd crush link", but that command isn't documented well and there are no examples of people using it in search results. So, this blog post is an attempt to seed the search engines. You would run something like this to get that host back in the default root: Or put it in a specific rack (like I wanted): I will preface this with, I am not a DBA. I've run PostgreSQL databases off and on for the past 8 years, but I'm not a full-time DBA. I don't follow all of the ins and outs and daily updates with PGSQL. I'm a simple bit pusher who runs a few dozen DB's. And with that out of the way..... I got an alarm last week about high disk usage on one of our PostgreSQL database instances. This was really odd as we've never seen a high disk alarm on them before. Also, it was just the master that was alarming; none of the replicas were alarming even though they have identically-sized drives. If the DB data were truly growing quickly, every machine would alarm. So I checked the DB size graphs in OpenNMS and sure enough, they were OK: 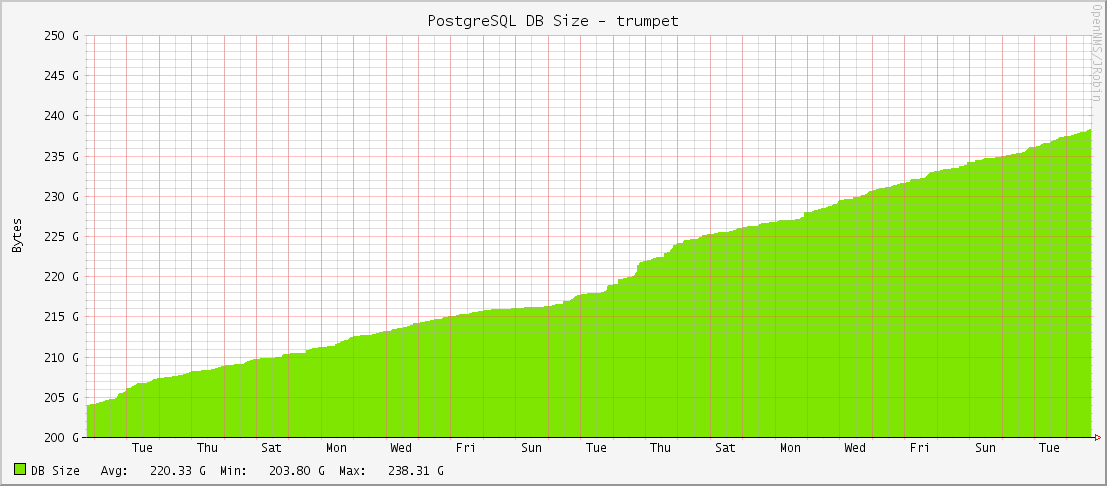 These are 1.6TB drives so nothing wild going on here. Running du in the pg_data directory showed that pg_xlogs were responsible for all of the new disk usage. But why? None of the WAL and checkpoint settings had been changed in months. Nothing new in the output logs. After searching high and low about the actual calculations for retaining WAL files (most of them are wrong including the official docs), I came to the conclusion that our WAL and checkpoint settings were not responsible for the high disk usage. But what was?
In the world of computing, there are some things which, in Dustin's words, "is not good software." For the past 6 months, I've been messing around with Ceph for object storage. Luckily for me, it is good software. However, it has bad documentation. Sometimes bordering horrible. This is the sorry state of opensource software these days (ever try an use a Hashicorp product lately?). While most things in Ceph are fairly automated, swapping an OSD's underlying storage device is not. Seems like a scale-out storage product would want to nail down the simple act of swapping a dead hard drive, right?
Sadly, the official documentation for swapping a drive is...long and not admin friendly. Seriously Ceph team, this is your suggested process? Red Hat is now Ceph's corporate overlord and even they think that this is an arduously bad process. Look, they even made a bug on it: https://bugzilla.redhat.com/show_bug.cgi?id=1210539 Luckily, I've figured out a much easier way. Here it is: 1. On the storage node, find the OSD # to drive letter mapping (sdq is the dying drive): We're still going through our CentOS 7 kickstart/build process here at Weebly, and we're uncovering new twists every day. There are the obvious ones like systemd, random packages renamed, and things like that. Luckily, the process for enabling LDAP UNIX users and groups (and authentication) is the same process in CentOS 7 as it is CentOS 6. Looks like they're sticking with sssd. It had a few issues once included in CentOS 6, but it seems stable and reliable. That's about the most you can ask for in an authentication provider.
Here's a link to my post about enabling LDAP auth in CentOS 6. It should work in CentOS 7 -- at least it did for us. Like many of you, I was pretty excited after T-Mobile made the Android 4.4.2 update (KitKat) available to the HTC One. After installing it, things seemed OK at first, and I was pleased with the new Sense tweaks.....Then my battery started to die. Rapido.
DISCLAIMER: This isn't a "bash redis" post. We use redis as a non-persistent key/value store here at Weebly and are happy with how it performs in that function. I'm thankful for all of the work Salvatore and the community have done into making redis a great key/value store. This post solely addresses using redis as a LRU cache replacement for memcached.
Ever since Danga Interactive's/LiveJournal's memcached burst on to the Internet scene, it has become the de facto general purpose caching application for people running larger scale Internet sites (or anyone just wanting to cache expensive operations). And why not? It's a pretty good program that's well written and has extensive library support. The major drawbacks to memcached are its slab allocator memory model and maximum object size at startup. Let's take a look at those. |
AuthorA NOLA native just trying to get by. I live in San Francisco and work as a digital plumber for the joint that runs this thing. (Square/Weebly) Thoughts are mine, not my company's.  Moi Archives
May 2021
Categories
All
|
 RSS Feed
RSS Feed