|
In my last post, I ventured into the topic of monitoring individual SSD health using Intel's SMART stats, specifically, the Media_Wearout_Indicator. I contrasted this to someone's approach of monitoring for total number of bytes written. In the post, I also threw out the idea of monitoring these counters with smartd. Well, smartd wouldn't do what I wanted it to do (watch this counter and throw a fit if it dropped below a value). Sooooo, I did what any UNIX admin would do and replaced it with a shell script. We use OpenNMS and NRPE to trigger commandlets like this, so here's the script I wrote. It should work in Nagios, too. You'll probably have to customize the script to your liking, but it's straightforward and has some easy to tweak variables in the beginning. If you can't figure these variables out, time find a new line of work. Full inline script after the jump (if you want to see what you can download).
Anand LaShimpi of Anandtech released an article on Intel SSD longevity a few days ago. A few of my friends were talking about it, so of course my boss asked me for numbers on our SSD longevity. First off, Anand is somewhat over-complicating things by trying to determine drive lifetime by how much data he's written so far. It's an admirable attempt, but it involves too much hedging and guessing. Managers and finance departments intensely dislike guessing. So what's a guy to use instead?
If you're working at a company that tries to save money by running LVS instead of dedicated load balancer appliances, you need to fetch your own monitoring data. No easy MIBs to read. The main LVS page basically says "use scripts" or "write a program using our library" which is fine and all. But there are a lot of people who need this stuff fast. So here it is. Here's how to grab the current input rate counters from LVS:
/usr/bin/tail -1 /proc/net/ip_vs_stats | /usr/bin/awk '{print strtonum("0x"$1), strtonum("0x"$2), strtonum("0x"$4)}' That command will spit out connections per second, packets in per second, and bytes in per second. The output stats are mostly useless if you run in direct return mode (as I assume most are). If you really need them: /usr/bin/tail -1 /proc/net/ip_vs_stats | /usr/bin/awk '{print strtonum("0x"$3), strtonum("0x"$5)}' We run this every minute through a cron entry and pipe the output to a file. The file is read via HTTP through a dedicated nginx instance that handles all of our internal profiling/stats data. OpenNMS does a regex match on it and then graphs the data. Done and done. The command will return errors if LVS isn't running, so you might want to make sure it's actually running. Good to see that FedEx will allow collisions on tracking numbers. One would think to use that as a primary key. Nope! Not FedEx! The phone call with the support rep was similarly hilarious. After assuring me that information I saw on my screen was wrong, my boss pointed out "well it's a good thing to know that they're using two systems here..." 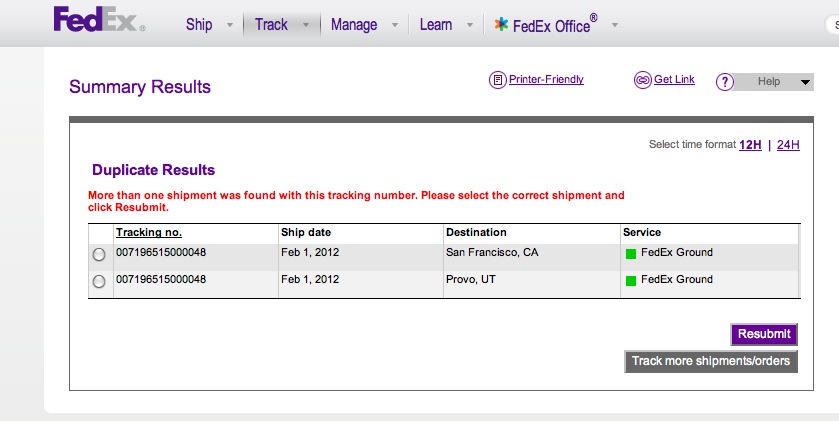 You didn't really think I'd stop with a single GTX 570 did you? Nah, it actually wasn't my plan to go down the SLI route. However, I did end up buying a nice big display -- a HP zr30w. It doesn't have the catchiest name, but it is a great display for the price range. Oh and sorry Apple fanboys, but this thing wipes the floor with your 30" display at a much lower cost. Jelz much? Anyway, back to the new loop. I took out the CPU cooler since liquid cooling really doesn't do much for the new socket 1155-based Intel CPUs like my Core i5-2500k. Honestly, the ability to dissipate heat isn't a huge deal for overclocking these CPUs -- it's a stable supply of power from the motherboard. Even when not overclocked, these guys don't throw off much heat. At load, mine runs at 55 celsius with the stock fan. Video cards, on the other hard, throw off heat like a nuclear reactor. So add one graphics card to the loop and remove the CPU. Here are some pics of the cards and the loop. I actually had to do this a few times since my first card from EVGA was a lemon. It would work for 10 minutes then die. Wasn't a heat issue. Something there was just busted. Got the card RMA'd easily (yay EVGA!) and fixed it all up. One thing I will say is that quick disconnects are fantastic! They make loop maintenance and changing soooo easy. No more draining your entire loop (of pricey fluid) just to change 1 thing. These things are great. Like all of the components here, I got my QD's from Koolance. I can't say the same thing for the Koolance 90-degree swivels. These things fail all over. Check their forums and you'll see the same thing. I've had a pair fail, and Koolance no longer uses that design. So that's about all you need to know. The newer static ones are supposedly better. Anyway, here are the pics. Yes, I did put tape on the memory controller things in the 2nd pic -- I didn't catch it at first. Also, you should put tape on the chokes. They don't get terribly hot but they are in the cool air flow of the normal stock cooler. So yeah, you should cool them. UPDATE - Sorry, I forgot to include some temps: Single GTX 570: Stock @ idle = 55c Liquid @ idle = 34c Stock @ load = 75c Liquid @ load = 47c SLI GTX 570: Stock @ idle = 55/60c Liquid @ idle = 36/39c Stock @ load = 75/78c Liquid @ load = 48/51c       |
AuthorA NOLA native just trying to get by. I live in San Francisco and work as a digital plumber for the joint that runs this thing. (Square/Weebly) Thoughts are mine, not my company's.  Moi Archives
May 2021
Categories
All
|
||

 RSS Feed
RSS Feed